
A journey through the challenges and triumphs when building a real-time streaming data warehouse.
Background
Our company previously relied solely on a transactional data warehouse. To enable more advanced analytics and machine learning capabilities, we implemented a new data warehouse solution. This new warehouse captured transactional data in real-time, stored it efficiently, and made it immediately accessible for reporting and analysis
Solution
To address the limitations of our transactional data warehouse and enable advanced analytics and machine learning, we identified our use cases, data needs, and performance goals. This led us to choose Databricks as our cloud-agnostic platform for its cost-effectiveness and streamlined technology stack.
Data Warehouse Architecture
We opted for a Data Vault 2.0 approach for its agility, scalability, flexibility, auditability, and consistency with our existing data governance practices.
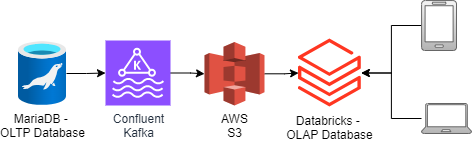
We created a data pipeline to move data from our transactional database (OLTP) to a cloud-based data storage (S3) using a series of tools and technologies. This process involved connecting our database to a messaging system (Kafka) and then transferring the data to S3. Finally, we transformed the data into a specific format (Data Vault 2.0) using Python and Spark within our data warehouse platform (Databricks).
Security
To ensure data security, we implemented role-based access controls to restrict access to sensitive information. Additionally, we established data retention policies to comply with regulatory requirements.
Monitoring and Automation
To ensure reliable and scalable pipeline execution, we implemented a logging and alerting system using New Relic and Databricks, alongside automating the entire pipeline with Python, AWS Lambda, and Databricks tools. This automation minimized resource usage, reduced costs, and improved reliability.
Team Leadership
While leading the team, I guided them in building data pipelines, Kafka infrastructure, and the analytical data warehouse in Databricks. I also facilitated discussions with leadership and stakeholders to navigate budgetary, resource, and time constraints, ensuring the best possible solution.
Navigating Challenges
Like any complex project, our data warehouse build faced challenges. These included data fragmentation, scalability bottlenecks, and costly performance issues. To address these, I collaborated with leadership, stakeholders, and the team to find the best solutions within our constraints.
Data Fragmentation
Challenge
With hundreds of clients, each having their own database, we faced the challenge of potential inconsistencies in data models and schemas. This fragmentation posed scalability limitations as we aimed to incorporate more clients into the new data warehouse.
Solution
To address data fragmentation from hundreds of client databases, we implemented a standardized data model. This involved extensive collaboration with leadership, infrastructure, DevOps, product, and account teams to ensure alignment across the organization. While this process took several months, it paved the way for a scalable data warehouse.
 To bridge the gap during this transition, I built an automated alerting system within Databricks using Python and SQL. This system monitored client data schemas in production and staging environments, notifying us of any discrepancies. This allowed us to account for changes and maintain data integrity in the pipeline and data warehouse.
To bridge the gap during this transition, I built an automated alerting system within Databricks using Python and SQL. This system monitored client data schemas in production and staging environments, notifying us of any discrepancies. This allowed us to account for changes and maintain data integrity in the pipeline and data warehouse.
Result
The implementation of the alerting system and standardized data model resulted in zero downtime for the OLAP data warehouse, significantly enhancing its reliability and performance. Additionally, the unified model ensured data consistency and scalability, enabling us to effectively support a growing number of clients without compromising data quality or system performance.
Scalability Bottleneck
Challenge
The time-consuming nature of client onboarding, which required 2-3 resources for 2-4 weeks, hindered our ability to scale operations and efficiently accommodate multiple clients. This limitation posed a significant challenge to our growth and scalability goals.
Solution
To address the scalability limitations, we developed an Infrastructure as Code (IaC) solution within Databricks. This automated the configuration and deployment of new client environments for the data warehouse, jobs, and reports. By automating these processes, we significantly reduced the time and effort required to onboard new clients, enhancing scalability and efficiency.
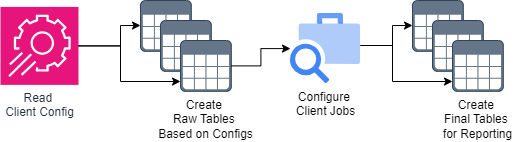
A Small Sample of the IaC
# config file
meta_tbl_df = spark.sql(
"""select * from {}.{}.{}""".format(META_CATALOG, META_SCHEMA, meta_table)
).cache()
table_catalog = meta_tbl_df.select("table_catalog").collect()[0][0]
tab_schema = meta_tbl_df.select("table_schema").collect()[0][0]
tables_from_meta = set(
meta_tbl_df.select(collect_set("table_name")).collect()[0][0]
)
# client dependent tables to create
available_tables = set(
spark.sql(
"""select collect_set(upper(table_name)) from {}.information_schema.tables where table_schema = '{}'""".format(
table_catalog, tab_schema
)
).collect()[0][0]
)
create_table_list = list(tables_from_meta - available_tables)
# configs for each of the client dependent tables
for tab in create_table_list:
tab_cols = (
meta_tbl_df.filter(meta_tbl_df["TABLE_NAME"] == tab.upper())
.selectExpr(
"collect_list(concat(COLUMN_NAME, ' ', DATA_TYPE, ' ', (case when IS_NULLABLE = 'NO' then 'NOT NULL' else '' end)))"
)
.collect()[0][0]
)
CONFIG_OPTION_1 = (
meta_tbl_df.select(upper("CONFIG_OPTION_1"))
.filter(meta_tbl_df["TABLE_NAME"] == tab.upper())
.collect()[0][0]
)
CONFIG_OPTION_2 = (
meta_tbl_df.select("CONFIG_OPTION_2")
.filter(meta_tbl_df["TABLE_NAME"] == tab.upper())
.collect()[0][0]
)
# create client dependent tables based on configs
create_table = (
"CREATE TABLE IF NOT EXISTS "
+ qualified_name
+ " (\n"
+ ",\n".join(tab_cols)
+ ")USING DELTA TBLPROPERTIES(DELTA.ENABLECHANGEDATAFEED = {}, delta.columnMapping.mode = '{}', delta.minReaderVersion = '{}', delta.minWriterVersion = '{}');".format(
CONFIG_OPTION_1,
CONFIG_OPTION_2,
)
)
Result
Thanks to the IaC solution, we achieved a significant reduction in the time and resources needed to onboard new clients. The process was streamlined from 2-4 weeks with 2-3 resources to 1-2 weeks with a single resource. This 500% improvement in efficiency directly contributed to our overall scalability and operational efficiency.
Costly Performance Issues
Challenge
Reports were taking too long to generate and were excessively expensive.
Solution
To enhance performance and reduce costs, I conducted a comprehensive analysis of SQL queries to identify optimization opportunities. Additionally, I guided the team in implementing effective data warehousing techniques such as partitioning, materialized views, and caching. These optimizations significantly improved query efficiency and reduced processing times.
To further optimize resource utilization, I conducted a thorough analysis of end-to-end reporting performance across various compute types. By examining factors like cluster CPU and memory utilization, traffic, storage, latency, and auto-scaling, I was able to identify the most suitable compute types for different job categories.
An Example of the Complexity of the SQL Joins
SELECT
...
FROM HUB_TARGETREQUEST H_TREQ
LEFT JOIN LINK_TARGETREQUEST_MPLAN L_TREQUEST_MPLAN
ON H_TREQ.HK_TARGETREQUEST_ID=L_TREQUEST_MPLAN.HK_TARGETREQUEST_ID
LEFT JOIN LINK_TARGETREQUEST_REQUEST L_TGTREQ_REQ
ON H_TREQ.HK_TARGETREQUEST_ID=L_TGTREQ_REQ.HK_TARGETREQUEST_ID
INNER JOIN SAT_TARGETREQUEST S_TGT_REQ
ON H_TREQ.HK_TARGETREQUEST_ID=S_TGT_REQ.HK_TARGETREQUEST_ID
INNER JOIN SAT_TARGETREQUEST_STATUS S_TGT_REQ_STS
ON S_TGT_REQ_STS.HK_TARGETREQUEST_ID=H_TREQ.HK_TARGETREQUEST_ID
AND S_TGT_REQ_STS.STATUS <> 'DELETE'
left join {SCHEMA}.hub_mplan hm
on L_TREQUEST_MPLAN.hk_mplan_id = hm.hk_mplan_id
left join (
select
*
from sat_locationtargetrequestadd sltra
where CDC_TIMESTAMP = (SELECT MAX(sltra_1.CDC_TIMESTAMP) FROM sat_locationtargetrequestadd sltra_1 WHERE sltra.hk_locationtargetrequestadd_id=sltra_1.hk_locationtargetrequestadd_id)
) sltra
on hm.id = sltra.mplanid
LEFT JOIN (
select
*
from sat_locationtargetrequestadd_status sltras
where sltras.CDC_TIMESTAMP = (SELECT MAX(sltras_1.CDC_TIMESTAMP) FROM sat_locationtargetrequestadd sltras_1 WHERE sltras.hk_locationtargetrequestadd_id=sltras_1.hk_locationtargetrequestadd_id)
AND sltras.STATUS <> 'DELETE'
) sltras
ON sltra.hk_locationtargetrequestadd_id = sltras.hk_locationtargetrequestadd_id
left join hub_list hl
on sltra.associatedobjectid = hl.id
left join link_list_stores lls
on hl.hk_list_id = lls.hk_list_id
left join hub_store hs
on lls.hk_store_id = hs.hk_store_id
where S_TGT_REQ.CDC_TIMESTAMP = (SELECT MAX(S_TGT_REQ_1.CDC_TIMESTAMP) FROM SAT_TARGETREQUEST S_TGT_REQ_1 WHERE S_TGT_REQ.HK_TARGETREQUEST_ID=S_TGT_REQ_1.HK_TARGETREQUEST_ID)
AND S_TGT_REQ_STS.CDC_TIMESTAMP = (SELECT MAX(S_TGT_REQ_STS_1.CDC_TIMESTAMP) FROM SAT_TARGETREQUEST_STATUS S_TGT_REQ_STS_1 WHERE S_TGT_REQ_STS_1.HK_TARGETREQUEST_ID=S_TGT_REQ_STS.HK_TARGETREQUEST_ID)
Result
The optimizations we implemented yielded substantial benefits, with a 90% performance boost and an 80% cost reduction. These improvements directly contributed to increased efficiency and cost savings.
Conclusion
Despite facing challenges such as data fragmentation, scalability bottlenecks, and costly performance issues, our team successfully implemented a robust data warehouse solution. Through collaboration and strategic decision-making, we overcame these obstacles and delivered a valuable asset to the organization.